Incode’s Technology
Frontier AI Lab for Fraud Prevention
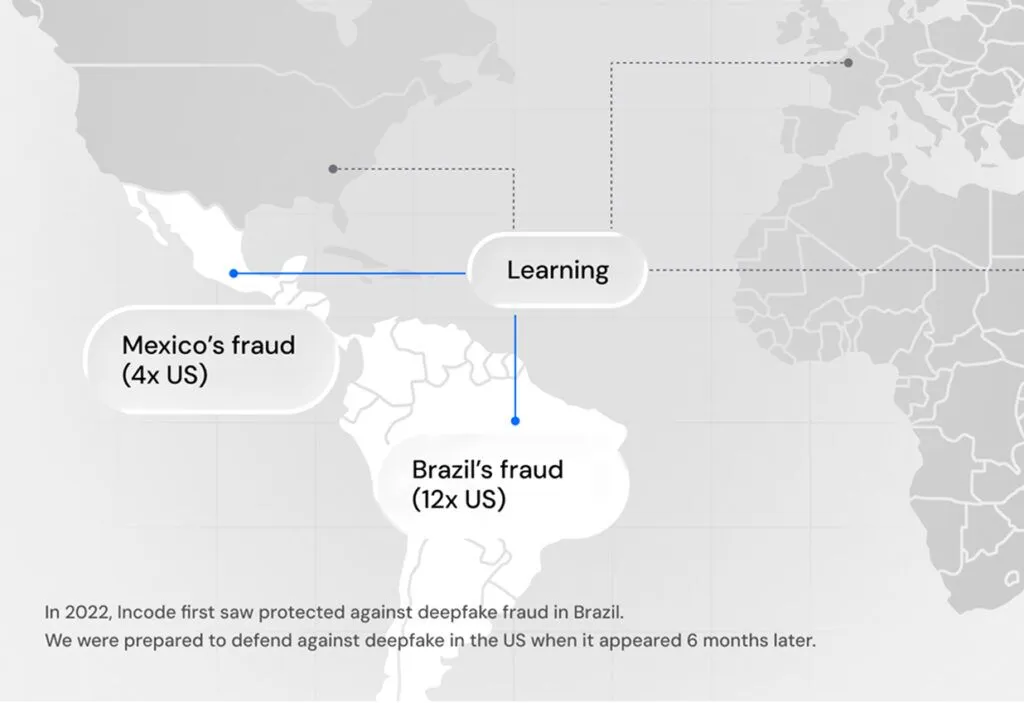
Incode is advancing the state of the art of AI models that identify and combat fraud. By leveraging foundational models trained on unique global fraud datasets and with the ability to continuously learn, Incode not only stops today’s fraud but also evolves at the speed of emerging gen-AI fraud threats.

.svg)

.svg)
.avif)
.avif)
.avif)




%20(1).avif)
%20(5)%20(1).avif)

.svg)
.svg)
.svg)
.svg)
.svg)


.avif)
.avif)
.avif)
.avif)
.avif)

.png)

%20(1).avif)
