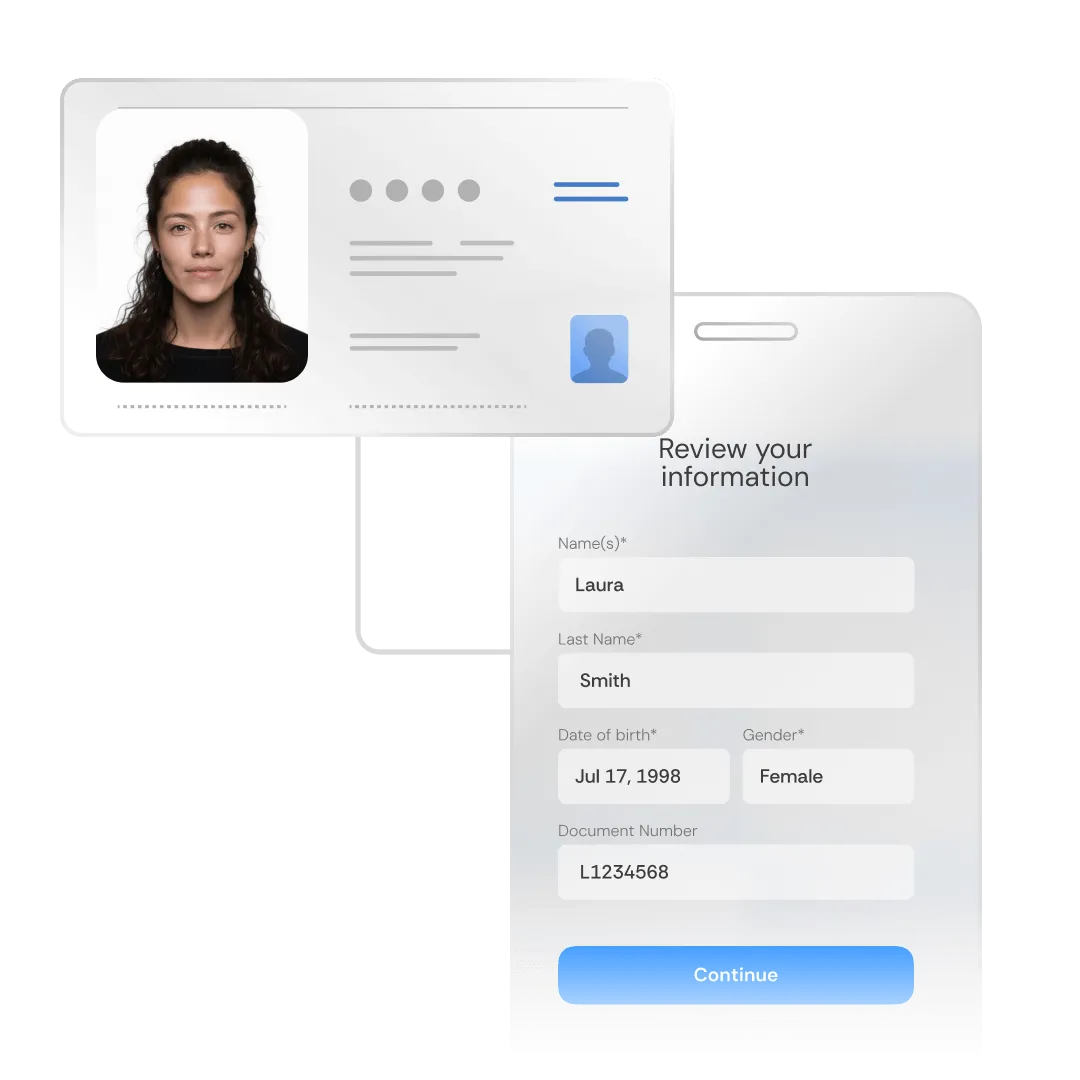
Nuestros modelos ML manejan todo el trabajo pesado, haciendo que cada interacción con el usuario se sienta sin esfuerzo. Al entregar mejores resultados, incluso en condiciones subóptimas, ahorramos tiempo a nuestros usuarios y minimizamos la necesidad de intervención manual.
Las características como la selección inteligente de cuadros, la detección automática de orientación de ID y la retroalimentación en tiempo real ayudan a garantizar que nuestro proceso sea sencillo y fácil de navegar. Al simplificar y acelerar el proceso, aumentamos las tasas de finalización e impulsamos las conversiones.

.svg)
.svg)
.svg)
.svg)

.svg)
.svg)

.svg)
.svg)
.svg)
.svg)

.svg)






.avif)

.avif)
.svg)
.avif)
.svg)



.svg)
.avif)

.avif)
.avif)
.avif)
.avif)

.avif)
.avif)
.avif)








.svg)







.avif)

.png)

%20(1).avif)
