.svg)

.svg)
.avif)
.avif)
.avif)




%20(1).avif)
%20(5)%20(1).avif)

.svg)
.svg)
.svg)
.svg)
.svg)


.avif)
.avif)
.avif)
.avif)
.avif)

.png)

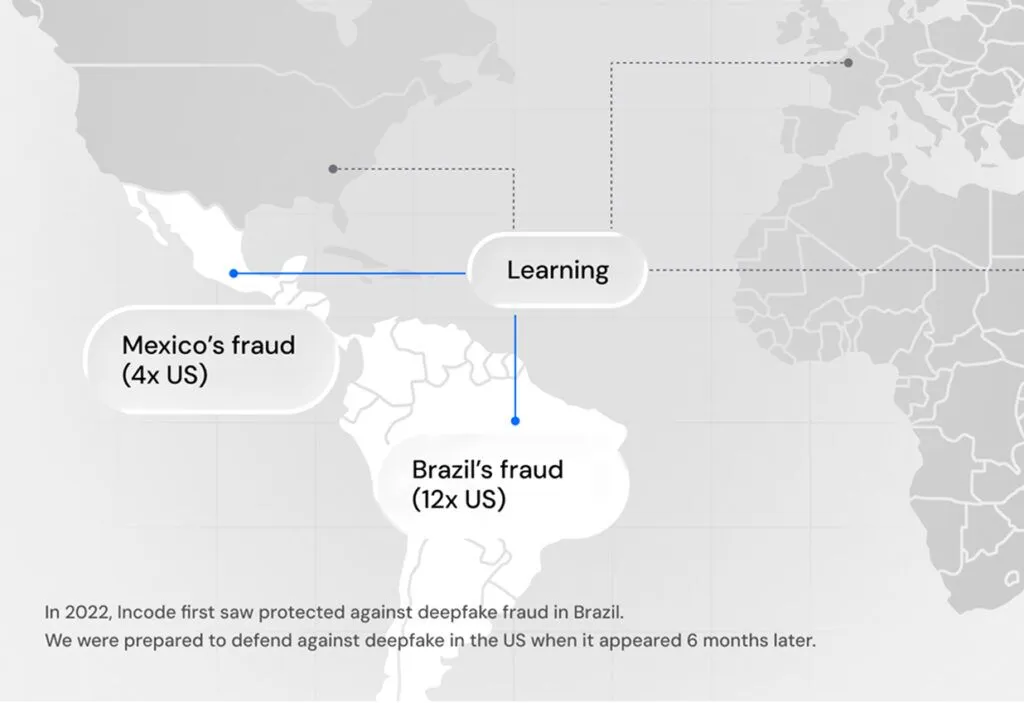
Incode operates a proprietary frontier AI lab developing custom models for facial recognition, liveness detection, document analysis, and deepfake detection — rather than relying on third-party AI components.
Tecnología de Incode
Laboratorio de IA de Frontier para la Prevención del Fraude
Incode está avanzando en el estado del arte de los modelos de IA que identifican y combaten el fraude. Al aprovechar modelos fundamentales capacitados en conjuntos de datos de fraude globales únicos y con la capacidad de aprender continuamente, Incode no solo detiene el fraude actual, sino que también evoluciona a la velocidad de las amenazas de fraude emergentes de la generación de IA.

%20(1).avif)
