El nuevo modelo de amenazas KYC: cuando los documentos se vuelven ejecutables

Konstantin Simonchik
May 10, 2026•

May 10, 2026•
Una demostración reciente en el [un] impulsó la Conferencia 2026 reveló un cambio de identidad que los equipos ya no pueden ignorar: en KYC impulsado por IA, los documentos ya no son entradas pasivas. Una vez OCR la salida llega a un agente de IA con acceso a herramientas, un archivo cargado puede convertirse en una superficie de ejecución no confiable.
![Sean Park on stage at [un]prompted 2026](https://cdn.prod.website-files.com/691faa7e1a497598820f663b/6a016a9d2440d95e417666f8_Sean%20Park%20on%20stage%20at%20%5Bun%5Dprompted%202026%20.png)
Sesión reciente de Sean Park en [un] incitó 2026 importó por una razón más profunda que “otra demostración de pasaporte falso”. El resumen oficial de Trend Micro muestra al equipo demostrado cómo un documento con inyecciones ocultas podría dirigir una canalización KYC impulsada por IA en lecturas y escrituras de registros cruzados.
La compañía lo enmarcó como una demostración de investigación, no como una brecha de producción descrita públicamente. En ese mismo resumen, Trend Micro describe la demostración utilizando una pila del mundo real construida con FastAPI, Claude Code y un backend SQLite MCP, y el equipo escaló el trabajo en 2,600 pruebas automatizadas en 13 modelos.
Eso cambia la conversación. Durante años, fraude de documentos en KYC se discutió principalmente como un problema de falsificación: IDs editados, recreación de plantillas, repeticiones de pantalla, identificaciones sintéticas.
Agentic AI añade un riesgo más fundamental. Ahora un documento puede ser falsificado y convertido en arma. Anthropic señala que cualquier agente que procese contenido no confiable está expuesto a un riesgo de inyección inmediata y enumera explícitamente documentos incrustados como parte de esa superficie de ataque.
OWASP va más allá, describiendo texto oculto, caracteres invisibles, trucos de metadatos, y las cargas útiles multimodales como patrones estándar de inyección rápida indirecta, y advierte que el exceso de agencia empeora mucho el impacto cuando los modelos pueden llamar a herramientas o interactuar con otros sistemas.
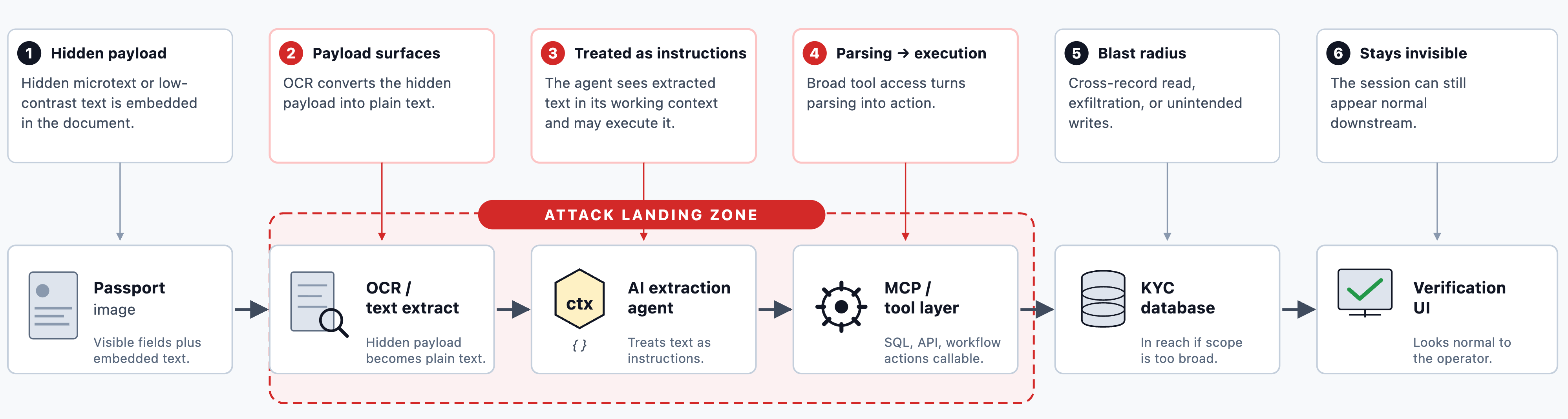
La parte más importante de esta historia no es el titular, es el punto de aterrizaje.
El ataque no se sienta en la toma de decisiones finales, y no depende de pasar por encima de los controles de acceso tradicionales. Atierra entre OCR o extracción de texto y orquestación de agentes.
El resumen de la conferencia describe los flujos de trabajo de KYC que delegan cada vez más el análisis de pasaportes, las escrituras de bases de datos y la verificación del cliente a agentes de extracción impulsados por IA.
Un resumen comunitario de la sesión publicó una diapositiva que muestra el flujo de extremo a extremo: Passport Image → OCR/Extracto de texto → AI Extraction Agent → SQLite MCP Server → Base de datos KYC → UI de verificación de usuario → KYC Complete.Ese es el punto ciego, el momento en que el documento deja de ser “solo una imagen” y se convierte en parte del contexto operativo del agente.
Esta es la razón por la que la arquitectura estándar tiene poca defensa en esa capa. La mayoría de las pilas de identidad se construyeron para controlar la calidad de captura, la viveza, la coincidencia de rostros, las listas de seguimiento, las reglas de políticas y los umbrales de aprobación final.
Pero una vez extraído, el texto del documento entra en un contexto LLM junto con las instrucciones del sistema (y el agente también puede llamar a las herramientas) la capa del analizador se convierte silenciosamente en una capa de ejecución.
La validación del esquema no resuelve eso. Un modelo no puede distinguir de manera confiable “datos de documentos” de “instrucciones ocultas dentro del documento” si ambos aparecen en el mismo contexto. Este es exactamente el problema al que OWASP apunta con la combinación de inyección rápida y agencia excesiva.
Arquitectónicamente, los proveedores más expuestos no son necesariamente los que tienen el OCR más débil. Ellos son aquellos cuya capa de ingestión es demasiado confiada. Tres patrones definen el riesgo:
Esa no es una acusación a nivel de marca. Es una inferencia arquitectónica: cuanto más cerca se encuentre la salida de OCR de un agente que llama a la herramienta sin aislamiento, mayor será el radio de explosión.
Para los equipos de identidad, el principio de diseño es simple pero estricto: la ingestión de documentos ya no puede diseñarse como “solo extracción”. Debe diseñarse como un límite de entrada no confiada.
Es por eso que la respuesta correcta no es un único modelo anti-falsificación, es una defensa en capas.
Incode se lanzó recientemente Deepsight para documentos, describiéndolo como un capa de detección de fraude de documentos generado por IA y basado en inyecciones dentro de los flujos de verificación de identidad existentes.
Incode describe tres capas coordinadas de detección de documentos: señales de comportamiento, integridad del dispositivo y análisis de capa de percepción impulsado por un Modelo de Lenguaje de Visión. más amplio Visión profunda los materiales también destacan la integridad de la cámara y la autenticidad de los documentos como parte de una defensa de verificación de viaje completo.
El tiempo importa. Incode reporta un Aumento de 9,7 veces en los intentos de fraude de documentos impulsados por Genai en los últimos dos años. En los mismos materiales públicos, la compañía dice que Deepsight for Documents capta 8.8x más sesiones fraudulentas que las comprobaciones tradicionales de documentos por sí solas, con un 0.04% tasa de rechazo falso.
En un conjunto de datos de equipo rojo controlado, Incode informa un 100% tasa de detección frente al 40% solo para la verificación estándar de identidad. Elimínese el lenguaje de marketing y el punto central es: la defensa de documentos debe ser nativa de la IA, capacitarse continuamente y estar diseñada para el fraude sintético y basado en inyecciones, no solo verificaciones estáticas de plantillas.
La historia no termina en la capa de documentos. Una sesión exitosa de documentos sintéticos rara vez permanece aislada, puede convertirse en la semilla para el fraude repetido, incorporación de mulas, o ataques coordinados. Ahí es donde la inteligencia de sesión y la inteligencia de redes se vuelven esenciales.
La dirección del producto de Incode se alinea bien con ese cambio. Agente de IA de riesgo se describe como una capa de decisión holística que pesa las señales en contexto y se adapta continuamente a los patrones de fraude y conversión.
De todo ello se desprende una pregunta más estratégica. A medida que las empresas se adentran más en los flujos de trabajo de los agentes, verificar sólo lo humano y el documento no será suficiente. También necesitarán saber qué agente está actuando, en nombre de quién, dentro de qué alcance, y bajo qué modelo de revocación.
Incode ya encuadra ese problema Identidad Agentica: vinculación verificada del propietario humano, consentimiento y tokenización con alcance, monitoreo conductual continuo e integraciones con MCP y otros protocolos agenticos. En lugar de un tema secundario, esta es la continuación lógica del mismo problema de confianza. Si los documentos pueden influir en los agentes, los propios agentes también deben formar parte del modelo de confianza y rendición de cuentas.
La lección principal de esta demostración no es que la IA deba eliminarse de KYC. El límite de confianza se ha movido. Los documentos cargados ya no son adjuntos pasivos sino entradas no confiables que pueden influir en el comportamiento del modelo y, a través de ese comportamiento, afectar a los sistemas conectados.
Arquitectura KYC moderna debe hacer cuatro cosas a la vez:
Ahí es donde se ganará la siguiente capa de confianza en las plataformas de identidad.
¿Listo para ver cómo Incode detecta el fraude de documentos generado por IA y basado en inyecciones? Explore Incode Deepsight para documentos.
%20(1).avif)
